Hadoop is an open-source software framework for storing data and running applications on clusters of commodity hardware. It provides massive storage for any kind of data, enormous processing power and the ability to handle virtually limitless concurrent tasks or jobs.

Before jumping into Apache Hadoop, Read about BigData. click here
So let's Talk about the History of Apache Hadoop

- Hadoop was created by Doug Cutting and Mike Cafarella in 2005.
- It was originally developed to support distribution for the Nutch search engine project.
- Doug, who was working at Yahoo! at the time and is now Chief Architect of Cloudera, named the project after his son's toy elephant.
- Cutting's son was 2 years old at the time and just beginning to talk.
- He called his beloved stuffed yellow elephant "Hadoop". Now, Doug's son often exclaims, "Why don't you say my name, and why don't I get royalties? I deserve to be famous for this!"
Hadoop Architecture

At its core, Hadoop has two major layers namely -
- Processing/Computation layer (MapReduce), and
- Storage layer (Hadoop Distributed File System-HDFS).
MapReduce
In simple terms MapReduce means Map the data and reduce
It has 3 stages
- Map stage
- Shuffle stage
- Reduce stage
Map stage - The map or mapper’s job is to process the input data. Generally, the input data is in the form of a file or directory and is stored in the Hadoop file system (HDFS). The input file is passed to the mapper function line by line. The mapper processes the data and creates several small chunks of data.
Shuffle - Sorting and Segregate
Reduce stage - This stage is the combination of the Shuffle stage and the Reduce stage. The Reducer’s job is to process the data that comes from the mapper. After processing, it produces a new set of output, which will be stored in the HDFS.
Example of MapReduce
HDFS
It is suitable for distributed storage and processing.
Hadoop provides a command interface to interact with HDFS.
The built-in servers of name node and data node help users to easily check the status of the cluster.
Streaming access to file system data.
HDFS provides file permissions and authentication.
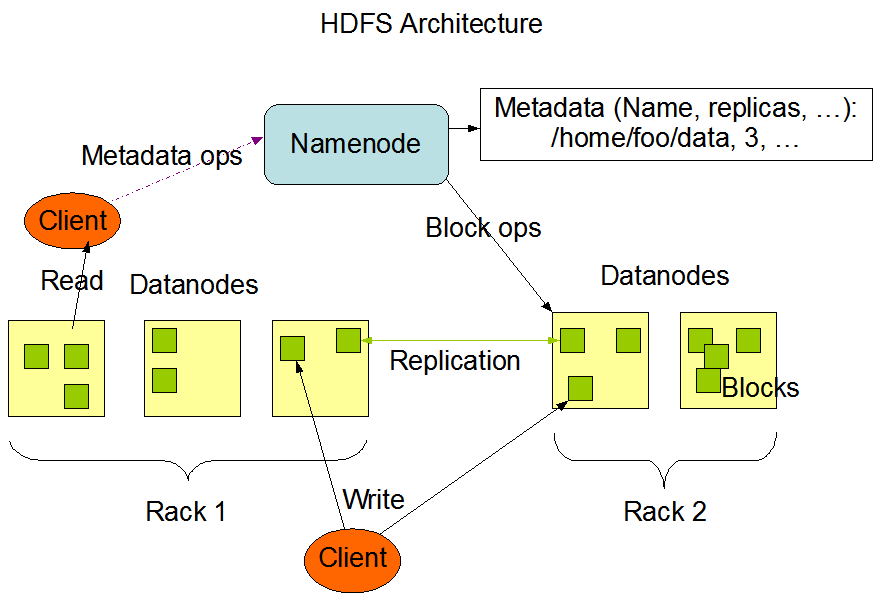
Working of HDFS
Online courses
For more info, you can read
https://hadoop.apache.org (official site)
x
This comment has been removed by the author.
ReplyDeleteThe post is really well written and presents an interesting piece of information, thank you. I was looking on Apache Hadoop for long. Now, I can make time to go through this and apply the information wherever I can. It will really help me to complete my assignment on Hadoop Training.
ReplyDelete